Policy Learning in Sim
Upon gathering the demonstrations, we learn a temporally-aligned and embodiment-agnostic + domain-agnostic reward function which is used for downstream RL policy learning.
Research on Inverse Reinforcement Learning (IRL) from third-person videos has shown encouraging results on removing the need for manual reward design for robotic tasks. However, most prior works are still limited by training from a relatively restricted domain of videos. In this paper, we argue that the true potential of third-person IRL lies in increasing the diversity of videos for better scaling. To learn a reward function from diverse videos, we propose to perform graph abstraction on the videos followed by temporal matching in the graph space to measure the task progress. Our insight is that a task can be described by entity interactions that form a graph, and this graph abstraction can help remove irrelevant information such as textures, resulting in more robust reward functions. We evaluate our approach, GraphIRL, by learning from human demonstrations for real-robot manipulation and via cross-embodiment learning in X-MAGICAL. We show significant improvements in robustness to diverse video demonstrations over previous approaches, and even achieve better results than manual reward design on real robot tasks.
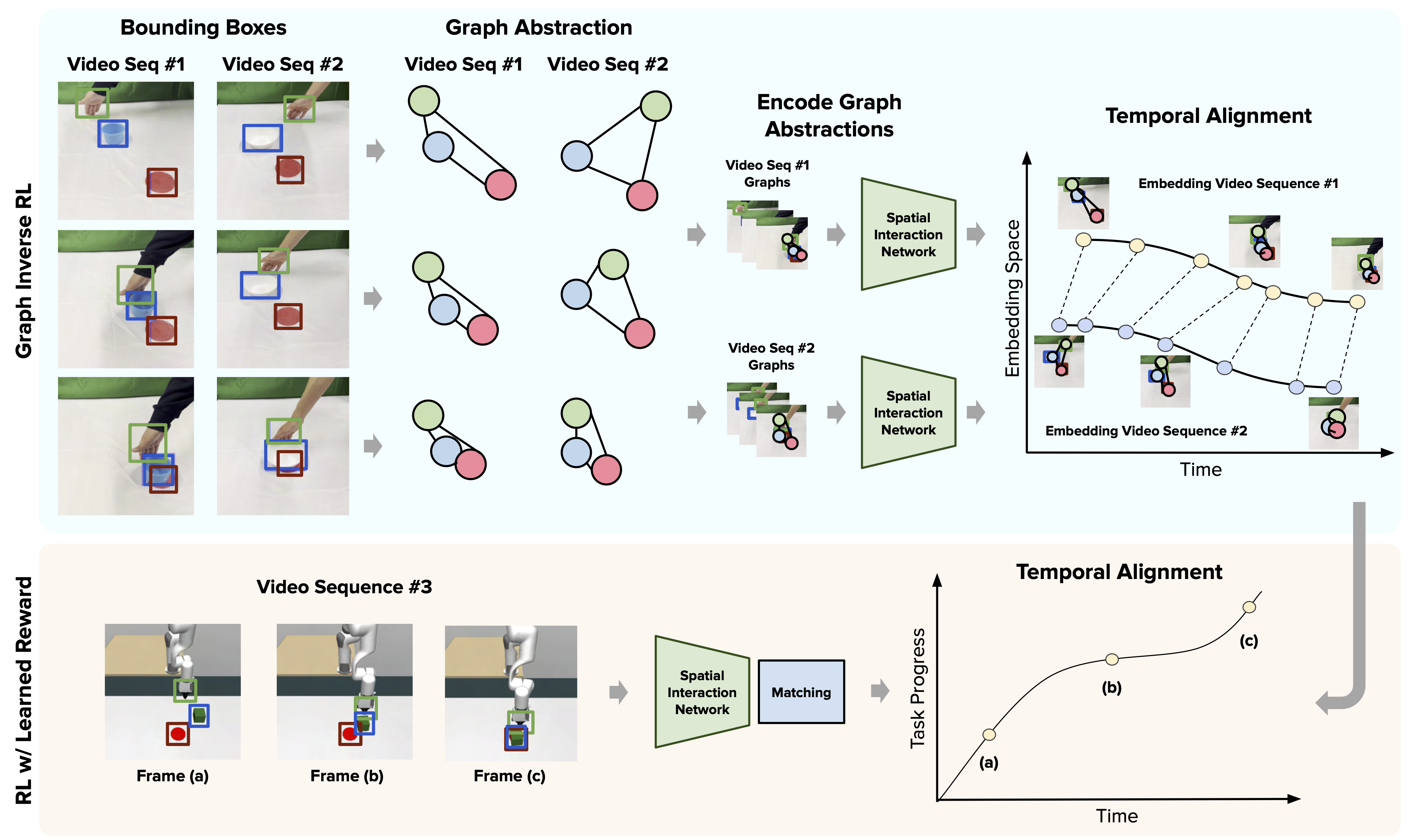
GraphIRL is a self-supervised method for learning a visually invariant reward function directly from a set of diverse third-person video demonstrations via a graph abstraction. Our framework builds an object-centric graph abstraction from video demonstrations and then learns an embedding space that captures task progression by exploiting the temporal cue in the videos. This embedding space is then used to construct a domain invariant and embodiment invariant reward function which can be used to train any standard reinforcement learning algorithm.
We have have 3 robotic manipulation tasks for which we gathered human demonstrations. From left-to-right, we have Task (a): Reach, Task (b): Push, and Task (c): Peg in Box. The video demonstrations have human hands completing the tasks with visually diverse goal regions, objects, and start-end locations for the human demonstrator.
Upon gathering the demonstrations, we learn a temporally-aligned and embodiment-agnostic + domain-agnostic reward function which is used for downstream RL policy learning.
We transfer the learned policies from simulation to a real robot and observe that our method achieves competitive success rates compared to other vision-based baselines.
We visualize the learned reward for the Peg in Box task in 2 success videos and 1 failure video.
In addition to evaluating GraphIRL on a range of robotic manipulation tasks, we also apply our method to the X-MAGICAL benchmark. With X-MAGICAL, we measure the performance of vision-based IRL baselines in the cross-embodiment cross-environment setting. For the purposes of our experiments, we leverage 2 variants of the X-MAGICAL environment: standard and diverse.
The goal for the agents in X-MAGICAL is to push three objects towards a static goal region. In the cross-embodiment cross-environment setting, we learn a reward function with GraphIRL on three of the four embodiments in one variant of the X-MAGICAL environment, and during RL, we use the learned reward function on an unseen embodiment in a visually different version of the environment.
If you use our method or code in your research, please consider citing the paper as follows:
@article{kumar2022inverse,
title={Graph Inverse Reinforcement Learning from Diverse Videos},
author={Kumar, Sateesh and Zamora, Jonathan and Hansen, Nicklas and Jangir, Rishabh and Wang, Xiaolong},
journal={Conference on Robot Learning (CoRL)},
year={2022}
}