|
I am a second year Computer Science PhD student at The University of Texas at Austin, advised by Prof. Roberto Martín-Martín and Prof. Georgios Pavlakos. My research focuses on the intersection of Robotics and Computer Vision. I hold a Master's degree from The University of California, San Diego where I was advised by Prof. Xiaolong Wang and a Bachelor's degree from FAST NUCES Karachi. In addition to my academic pursuits, I have gained industry experience as a Generative AI Researcher at TikTok and as a Computer Vision Research Engineer at Retrocausal. Email / CV / Google Scholar / Twitter |

|
|
|
*: Equal Contribution. †: Equal Advising. |

|
Sateesh Kumar, Shivin Dass, Georgios Pavlakos†, Roberto Martín-Martín†, Conference on Robot Learning (CoRL) , 2025 project page / arXiv COLLAGE is a few-shot imitation learning method that adaptively fuses demonstrations from multiple similarity modalities. It estimates each modality’s usefulness by training a policy on its retrieved data and measuring how probable the target actions are under that policy. |
|
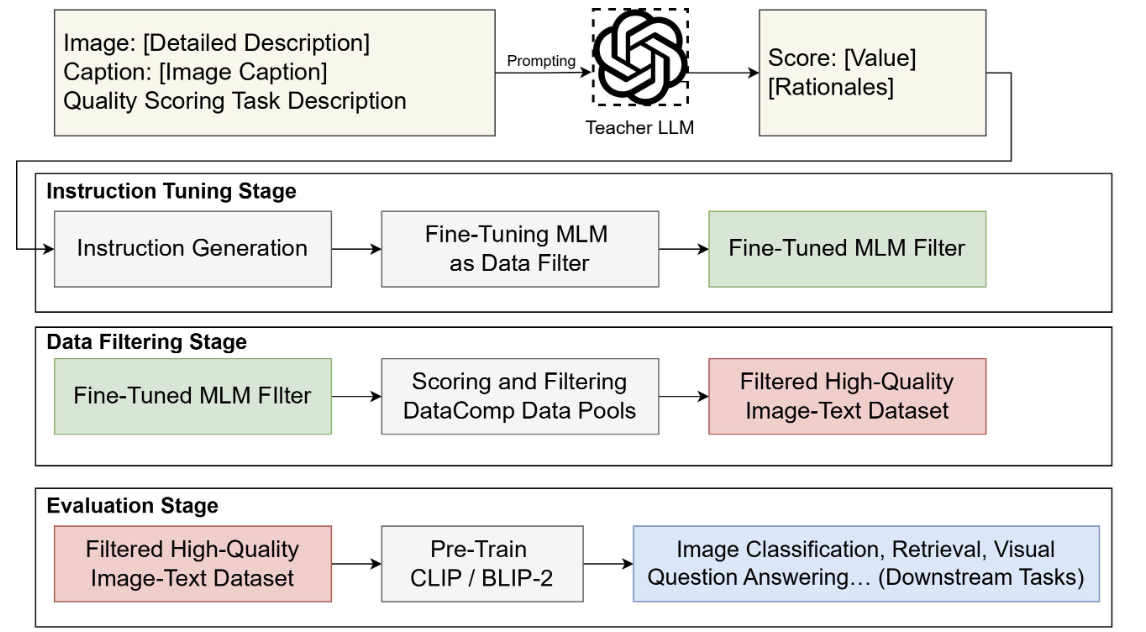
Weizhi Wang, Khalil Mrini, Linjie Yang, Sateesh Kumar, Xifeng Yan Heng Wang, arxiv , 2024 project page / arXiv This paper introduces a method that uses finetuned multimodal language models to filter image–text pairs more accurately than traditional metrics like CLIPScore. It defines multiple specialized quality metrics and builds instruction tuning data guided by stronger models such as GPT-4 to train the models to score data effectively. The result is a reliable and efficient filter that better evaluates image–text alignment. |
|
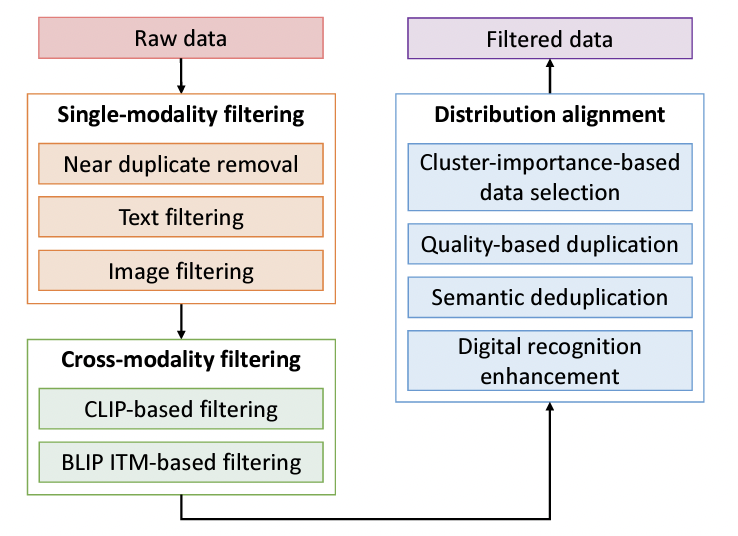
Haichao Yu, Yu Tian, Sateesh Kumar, Linjie Yang, Heng Wang International Conference on Computer Vision (ICCV) DataComp Workshop , 2023 (Ranked 1st in DataComp challenge) arXiv We introduce a three-stage filtering strategy for enhancing model performance. It focuses on single-modality filtering, cross-modality filtering, and data distribution alignment. The proposed approach significantly surpasses previous methods on the DataComp benchmark. |
|
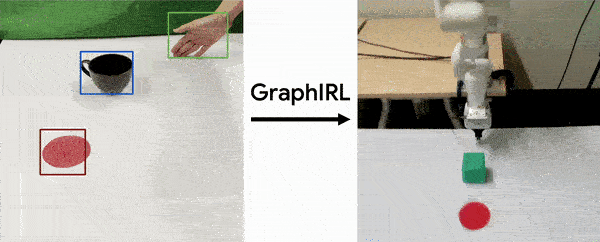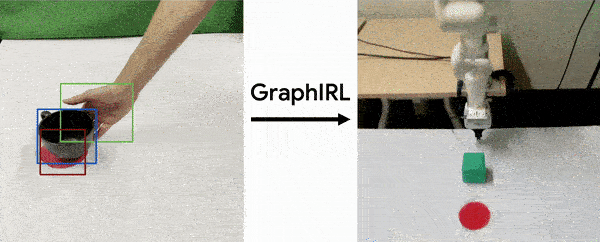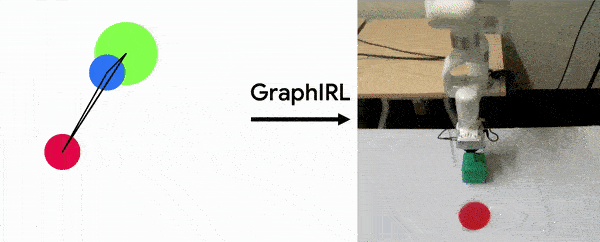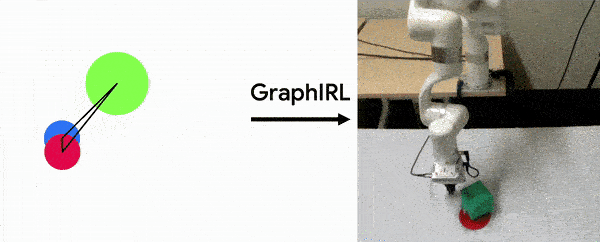
Sateesh Kumar, Jonathan Zamora*, Nicklas Hansen*, Rishabh Jangir, Xiaolong Wang Conference on Robot Learning (CoRL) , 2022 (Oral) project page / arXiv GraphIRL is a self-supervised method for learning a task reward solely from videos. We build an object-centric graph abstraction from video demonstrations and then learn an embedding space that captures task progression in a self-supervised manner by exploiting the temporal cue in the videos. |

|
Sateesh Kumar*, Sanjay Haresh*, Awais Ahmed, Andrey Konin , M. Zeeshan Zia, Quoc-Huy Tran CVPR, 2022 project page / arXiv We propose temporal optimal transport for jointly learning representations and performing online clustering in an unsupervised manner. The approach learns prototype vectors via backpropogation. The prototype vectors are initialized at random and act as cluster centroids. |

|
Sateesh Kumar*, Sanjay Haresh*, Huseyin Coskun, Shahram N. Syed, Andrey Konin , M. Zeeshan Zia, Quoc-Huy Tran CVPR, 2021 project page / arXiv We propose alignment as pre-text task for self-supervised video representation learning. The proposed approach leverages differentiable dynamic time warping for learning global alignment across pairs of videos. |

|
Sateesh Kumar*, Sanjay Haresh*, M. Zeeshan Zia Quoc-Huy Tran IV, 2020 talk / arXiv We collect a video dataset of road-based anomalies. We propose an object-object interaction reasoning approach for detecting anomalies without additional supervision. We experiment with reconstruction based and one-class classification based approaches. |
|
Website layout is from Jon Barron |